云计算产品与技术深度解析 聚焦云存储与数据处理服务
在数字化转型浪潮中,云计算已成为现代企业不可或缺的技术基石。其中,云存储与数据处理服务作为核心组成部分,不仅重塑了数据管理方式,更驱动了业务创新与效率提升。本文将系统梳理这两大领域的关键产品与技术,揭示其如何协同构建智能、弹性且安全的数据基础设施。
一、 云存储服务:数据的“数字家园”
云存储服务提供了在远程服务器上存储、管理和访问数据的能力,按需付费,弹性伸缩。其主要可分为以下几类:
- 对象存储:
- 核心特性:适用于海量非结构化数据(如图片、视频、日志文件),通过唯一的标识符(如URL)进行访问。具备极高的可扩展性、耐用性和成本效益。
- 代表产品:亚马逊S3、阿里云OSS、腾讯云COS。这些服务通常提供多冗余备份、版本控制、生命周期管理等功能。
- 块存储:
- 核心特性:为云服务器提供如同本地硬盘般的高性能、低延迟存储卷,可格式化文件系统并安装操作系统。适用于数据库、企业应用等需要高性能随机读写的场景。
- 代表产品:AWS EBS、Azure Disks、华为云EVS。支持SSD和HDD等多种介质,并可独立于计算实例存在。
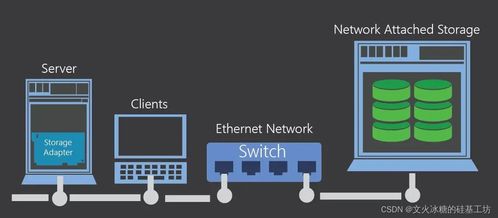
- 文件存储:
- 核心特性:提供标准的文件系统接口(如NFS、SMB),允许多个计算实例共享访问同一套文件。适合内容管理、媒体处理及开发团队协作等场景。
- 代表产品:AWS EFS、Azure Files、Google Cloud Filestore。
- 归档与冷存储:
- 核心特性:针对极少访问的长期保存数据,提供极低的存储成本,但检索速度较慢,可能产生取回费用。是合规备份和历史数据归档的理想选择。
- 代表产品:AWS Glacier、Azure Archive Storage、阿里云归档存储。
二、 数据处理与存储服务:从数据湖到智能洞察
数据处理服务与存储紧密结合,旨在将原始数据转化为有价值的洞察。其技术栈涵盖采集、存储、处理、分析与服务化全流程。
- 大数据存储与计算平台:
- 数据湖:以对象存储为核心,集中存储所有结构化和非结构化数据,形成企业级的统一数据仓库。AWS Lake Formation、阿里云Data Lake Formation等产品提供了快速构建、管理和保护数据湖的能力。
- 大数据计算引擎:
- 批处理:如基于Hadoop的EMR(Amazon EMR, 阿里云E-MapReduce)或Spark服务,用于处理海量历史数据。
- 流处理:如Apache Flink(阿里云实时计算Flink版)、Amazon Kinesis、Google Cloud Dataflow,用于实时处理数据流。
- 数据仓库与湖仓一体:
- 云数据仓库:专为大规模结构化数据分析优化,性能远超传统数据库。代表产品如Snowflake、Amazon Redshift、Google BigQuery、阿里云MaxCompute。它们支持PB级数据查询,并具备强大的并发能力。
- 湖仓一体:新兴架构,融合了数据湖的灵活性与数据仓库的性能与管理能力。Databricks Lakehouse Platform、AWS Athena(直接在S3上使用SQL查询)是典型实践。
- 数据库即服务:
- 关系型数据库:全托管服务,如Amazon RDS、Azure SQL Database、阿里云RDS,支持MySQL、PostgreSQL等主流引擎,自动化运维。
- NoSQL数据库:针对特定场景优化。
- 键值存储:如Amazon DynamoDB、阿里云Table Store,适用于高并发读写。
- 文档数据库:如MongoDB Atlas、Azure Cosmos DB,存储JSON类文档。
- 宽列存储:如Google Bigtable、阿里云HBase,适合时序、物联网数据。
- 图数据库:如Amazon Neptune,用于处理复杂关系网络。
- 数据集成与编排:
- 服务如AWS Glue(元数据目录与ETL)、Azure Data Factory、阿里云DataWorks,提供可视化的数据抽取、转换、加载流程编排,是实现数据管道自动化的关键。
- AI赋能的数据分析:
- 云厂商将机器学习能力深度集成。例如,Amazon S3 Intelligent-Tiering可自动将数据移至最具成本效益的存储层;BigQuery ML允许用户直接用SQL创建和运行机器学习模型。
三、 核心优势与技术趋势
- 核心优势:
- 弹性与可扩展性:资源随业务需求动态伸缩。
- 成本优化:从资本支出转向运营支出,按实际使用量付费。
- 高可用与持久性:跨可用区、跨地域的冗余设计保障数据安全。
- 简化运维:全托管服务解放了企业的运维负担。
- 安全与合规:提供加密、访问控制、审计日志等全方位安全能力。
- 技术趋势:
- 统一与融合:“湖仓一体”架构正成为主流,打破数据孤岛。
- 智能化:AIops用于自动性能调优、成本管理与安全防护。
- 云边端协同:数据处理向边缘延伸,满足低延迟和本地化处理需求。
- Serverless化:如AWS Aurora Serverless、Google BigQuery,进一步实现无服务器计算,用户只需关注业务逻辑。
- 开源与多云:基于开源生态(如Kubernetes、Spark)构建的服务增强了可移植性,多云策略避免厂商锁定。
###
云存储与数据处理服务共同构成了云计算时代的数据基座。从灵活经济的对象存储,到高性能的块存储,再到智能融合的湖仓一体平台,技术的演进始终围绕着让数据更易存、易管、易用。深入理解并合理选用这些服务,是释放数据潜能、构建竞争优势的关键一步。随着人工智能与云计算的深度融合,数据服务将变得更加自动化、智能化,持续赋能千行百业的创新与增长。
如若转载,请注明出处:http://www.52animal.com/product/71.html
更新时间:2026-06-19 02:35:52