Python数据分析实战 抓取课工厂网站数据、处理与存储全流程解析
在数据驱动的时代,Python凭借其丰富的库和简洁的语法,已成为数据获取、处理与分析的首选工具之一。本文将通过一个完整的实例,详细介绍如何使用Python抓取“课工厂”网站的数据,并进行清洗、分析与存储,构建一套自动化数据处理与存储服务。
一、项目目标与准备工作
本项目旨在从“课工厂”网站(一个假设的教育类网站,提供各类在线课程信息)上抓取课程数据,包括课程名称、讲师、价格、评分、学习人数等关键信息。通过对这些数据进行处理与分析,我们可以洞察课程市场的趋势、热门领域及用户偏好。
准备工作包括:
- 环境配置:安装Python(建议3.7及以上版本)及必要的库,如requests(用于网络请求)、BeautifulSoup或lxml(用于HTML解析)、pandas(用于数据处理与分析)、sqlalchemy(用于数据库操作)等。
- 目标分析:手动浏览“课工厂”网站,分析其页面结构、URL规律及数据存放的标签,为编写爬虫程序奠定基础。
- 法律与伦理:确保爬虫行为遵守网站的robots.txt协议,并设置合理的请求间隔,避免对目标网站造成过大负载。
二、数据抓取:构建稳健的爬虫程序
数据抓取是第一步,我们使用requests库发送HTTP请求,并利用BeautifulSoup解析返回的HTML页面,提取所需的结构化数据。
关键步骤:
- 模拟请求头:设置User-Agent等头部信息,模拟浏览器访问,降低被反爬机制拦截的风险。
- 分页处理:分析课程列表页的URL分页规律(如
?page=1),通过循环遍历所有页面,确保抓取数据的完整性。 - 数据提取:针对每个课程详情页,定位并提取目标数据字段。例如,课程名称可能位于
<h1 class="course-title">标签内,价格信息可能在<span class="price">中。 - 异常处理与延时:添加try-except块处理网络异常或解析错误,并利用time.sleep()在请求间加入随机延时,体现良好的爬虫礼仪。
- 数据暂存:将每次循环抓取到的数据以字典形式存入列表,为后续处理做准备。
示例代码片段(仅展示核心逻辑):`python
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
baseurl = "https://www.kegongchang.com/courses"
datalist = []
for page in range(1, 11): # 假设抓取前10页
url = f"{baseurl}?page={page}"
headers = {'User-Agent': 'Mozilla/5.0'}
try:
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
courses = soup.findall('div', class='course-item') # 假设的课程容器
for course in courses:
coursedata = {}
coursedata['title'] = course.find('h2').text.strip()
coursedata['instructor'] = course.find('span', class='instructor').text.strip()
coursedata['price'] = course.find('div', class_='price').text.strip()
# 更多字段提取...
datalist.append(coursedata)
time.sleep(1) # 礼貌延时
except Exception as e:
print(f"抓取第{page}页时出错: {e}")`
三、数据处理:清洗、转换与丰富
抓取的原始数据往往存在缺失值、格式不一致等问题,需通过pandas进行清洗和转换,使其适合分析。
核心处理环节:
- 创建DataFrame:将抓取的数据列表转换为pandas DataFrame,便于后续操作。
- 数据清洗:
- 处理缺失值:使用
fillna()填充或dropna()删除缺失数据。
- 格式标准化:例如,将价格字段从字符串(如“¥199”)转换为数值类型,移除货币符号并转换为浮点数。
- 去重处理:基于课程ID或标题去除可能存在的重复记录。
- 数据转换与衍生:
- 分类标签:根据课程标题或描述,提取关键词或进行分类(如“编程”、“设计”、“商业”)。
- 评分分段:将连续评分转换为“高”、“中”、“低”等级别,便于分组分析。
- 数据验证:检查处理后的数据分布与基本统计信息,确保数据质量。
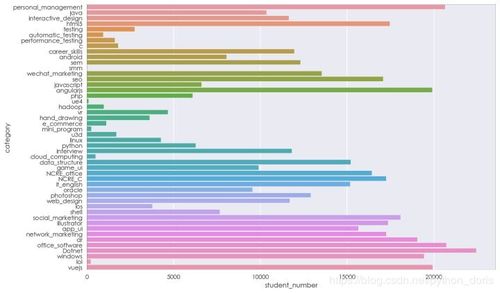
四、数据分析:挖掘洞察与可视化
利用pandas的数据聚合、分组功能,结合matplotlib或seaborn进行可视化,我们可以从多个维度分析课程数据。
可能的分析方向:
- 总体概览:统计课程总数、平均价格、平均评分等。
- 价格分析:计算不同类别课程的价格分布、中位数及高价/低价课程占比。
- 热度分析:根据学习人数或评分,找出最受欢迎的课程及讲师。
- 关联分析:探索价格、评分、学习人数等变量间的相关性。
示例分析代码:`python
import matplotlib.pyplot as plt
假设df为处理后的DataFrame
按课程类别统计平均价格
avgpricebycategory = df.groupby('category')['price'].mean().sortvalues()
绘制柱状图
avgpricebycategory.plot(kind='bar')
plt.title('各课程类别平均价格')
plt.xlabel('课程类别')
plt.ylabel('平均价格(元)')
plt.tightlayout()
plt.show()`
五、数据存储:构建持久化服务
分析完成后,需要将原始数据及处理结果持久化存储,以便后续使用或集成到其他应用中。常见的存储方案包括:
1. 文件存储:将DataFrame保存为CSV、Excel或JSON文件,便于分享与快速查看。
`python
df.tocsv('kegongchangcourses.csv', index=False, encoding='utf-8-sig')
`
2. 数据库存储:使用SQLAlchemy将数据存入SQLite、MySQL或PostgreSQL等关系型数据库,便于复杂查询与管理。
`python
from sqlalchemy import create_engine
# 创建SQLite数据库引擎
engine = create_engine('sqlite:///courses.db')
# 将DataFrame存入名为'courses'的表
df.tosql('courses', engine, ifexists='replace', index=False)
`
- 云存储或数据仓库:对于大规模数据,可以考虑上传至云存储(如AWS S3)或导入到数据仓库(如Google BigQuery)中,支持更强大的分析能力。
六、服务化与自动化
为使整个流程可持续运行,我们可以将上述步骤脚本化,并加入定时任务(如使用cron或APScheduler)实现定期自动抓取与更新。进一步,可以封装为简单的Web服务(使用Flask或FastAPI),提供数据查询接口,或生成自动化分析报告并通过邮件发送。
通过这个从抓取、处理、分析到存储的完整案例,我们展示了Python在数据分析项目中的强大能力。它不仅帮助我们高效获取网络数据,还能通过系统的处理与分析,将原始信息转化为有价值的商业洞察。在实际应用中,请务必根据目标网站的具体结构调整代码,并始终遵守相关法律法规与道德准则。
如若转载,请注明出处:http://www.52animal.com/product/58.html
更新时间:2026-06-19 03:04:49